Fan Shiqing @Xiamen University
实验环境安装
Linux:Ubuntu16.04
Java:1.7.0_80
Hadoop:2.7.1
Python:2.7
PyCharm:2019.1.2(Community Edition)
matplotlib:2.0.0
Spark:2.1.0
下载数据集
数据集为某音乐平台歌曲《同桌的你》评论者的信息数据,包含评论者的用户ID、动态总数、关注总数、粉丝总数、所在地区、个人介绍、年龄、累计听歌总数属性。共4752条数据,部分如下图: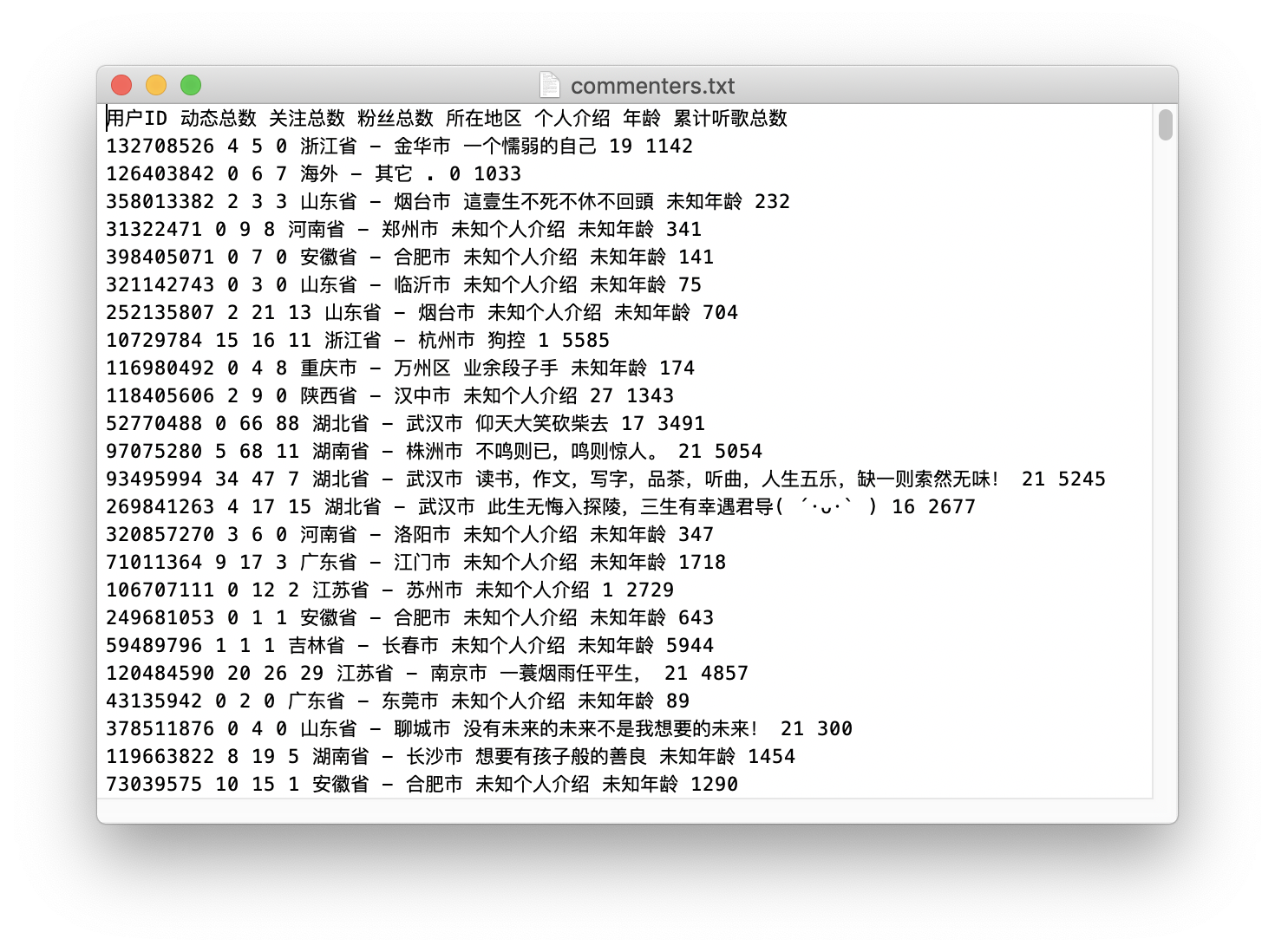
数据集的预处理
- 将txt文件转为csv文件
- 修改文件属性名称方便读写
使用Spark进行数据分析
读入数据并筛选需要用到的属性
1
2
3
4
5sc =SparkContext()
sqlContext = SQLContext(sc)
data = sqlContext.read.format('com.databricks.spark.csv').options(header='true', inferschema='true').load('commenters.csv')
list = ['ID', 'fans', 'province', 'city', 'age', 'songs']
data = data.select([column for column in data.columns if column in list])查看数据、显示数据的结构
1
2
3
4print "【展示10行数据】"
data.show(10)
print "【数据结构】"
data.printSchema()
1 | 【展示10行数据】 |
- 将年龄、听歌数量改为integer类型,以便进行数据统计
1
2data = data.withColumn("age", data["age"].cast(IntegerType()))
data = data.withColumn("songs", data["songs"].cast(IntegerType()))``
1 | 【数据类型转换】 |
- 查找评论者当中听歌最多的人的歌曲数量
1
data.select(max('songs')).show()
1 | 【评论者最多听歌数量】 |
- 统计《同桌的你》的评论者所在地区的分布情况
1 | area = data.groupBy('province').count().orderBy(col("count").desc()) |
1 | 【评论者所在地区分布】 |
- 统计《同桌的你》的评论者的年龄的分布情况
1
age = data.groupBy('age').count().orderBy(col("count").desc())
1 | 【评论者年龄TOP10】 |
- 统计《同桌的你》的评论者所在各个地区的听众平均年龄
1
mean = data.groupBy('province').agg({"age": "mean"})
1 | 【各个地区平均年龄情况】 |
- 统计《同桌的你》的评论者的粉丝数量情况
1
fans = data.groupBy('fans').count().orderBy(col("count").desc())
1 | 【评论者粉丝数量】 |
可视化呈现
将数据分析的结果通过matplotlib可视化显示出来
(在实验时,中文一直出错无法显示,暂用拼音和英文代替)
《同桌的你》的听众所在地区的分布情况
从图中看出,这首歌曲广东省的听众远超过其他地区。
《同桌的你》听众年龄分布
从图中看出,这首歌的听众20-30岁之间的居多,另外33岁的听众非常多。
有部分因素是网络歌曲平台的受众大部分在于这个年龄阶段。
《同桌的你》各个区域听众平均年龄
平均年龄基本上在17-27岁之间。
听众粉丝数量情况
大部分听众的粉丝数量低于10。