NIPS 2012 《ImageNet Classification with Deep Convolutional Neural Networks》
Alex Krizhevsky | Ilya Sutskever | Geoffrey E. Hinton
PaperLink
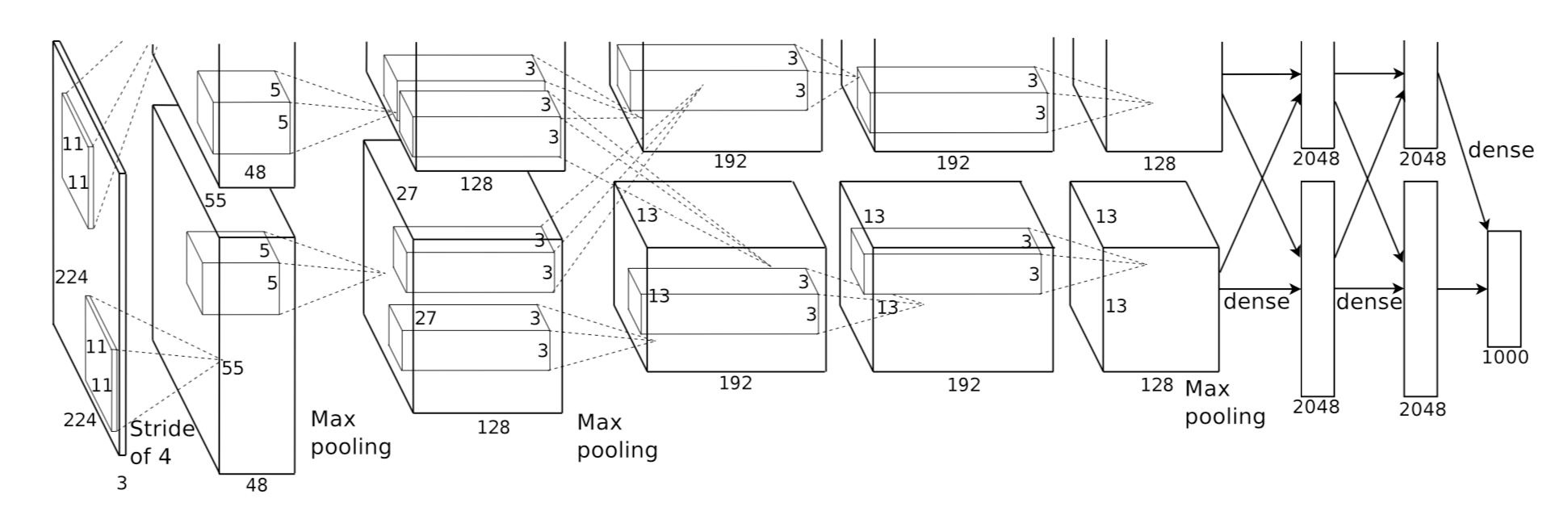
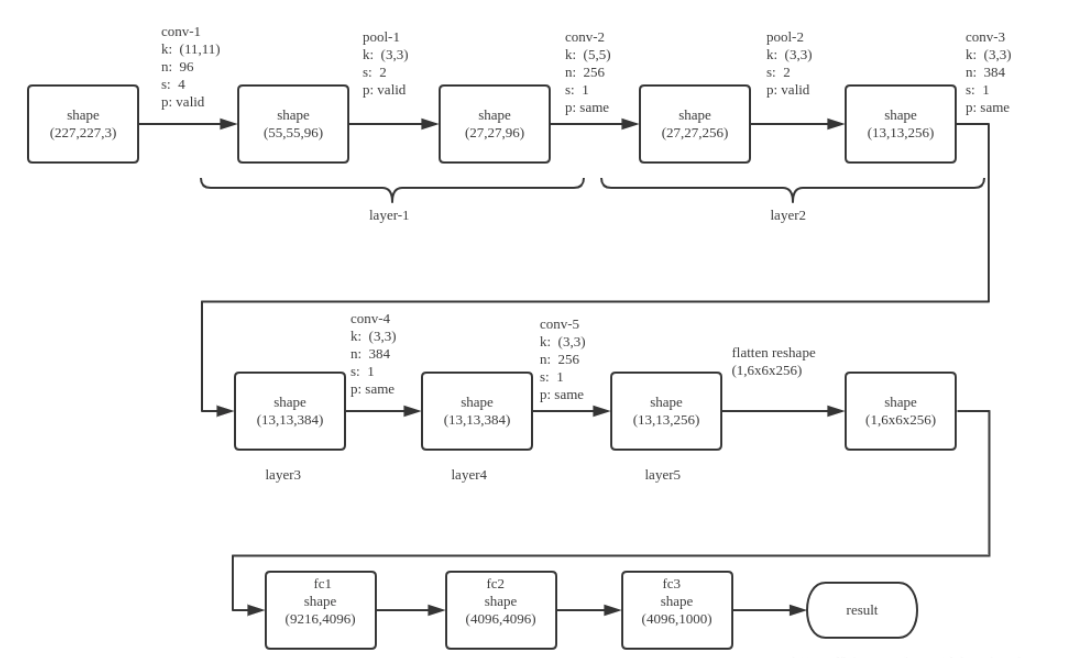
基本参数
input: 224×224大小的图片,3通道
conv1: 11×11大小的卷积核96个,每个GPU上48个。
max-pooling: 2×2的核。
conv2: 5×5卷积核256个,每个GPU上128个。
max-pooling: 2×2的核。
conv3: 与上一层是全连接,3x3的卷积核384个。分到两个GPU上个192个。
conv4: 3×3的卷积核384个,两个GPU各192个。该层与上一层连接没有经过pooling层。
conv5: 3×3的卷积核256个,两个GPU上个128个。
max-pooling: 2×2的核。
FullyConnected1: 4096维,将第五层max-pooling的输出连接成为一个一维向量,作为该层的输入。
FullyConnected2: 4096维
Softmax: 输出为1000,输出的每一维都是图片属于该类别的概率。
一些操作
ReLU
使用非线性饱和函数ReLU作为神经元激活函数$f(x)=max(0,x)$
数据增强
- 随机抓取224x224的小块,以及它的水平翻转:
从256x256的图片中抓取224x224的小块,并用这抓取的小块来训练网络;
使训练集增加了2048倍,但是样本间有高度依赖性;
不使用这个方案时,出现大量的过拟合;
测试阶段时,抓取5个224x224的小块以及它们的水平翻转(共10个)来做预测,并对这10个小块的softmax预测值做平均。 - 改变训练图像中的RGB通道的强度:
遍历ImageNet训练集,在RGB像素值的集合上使用PCA
使已知的主成分加倍
比例为对应特征值乘以一个随机变量
随机变量服从均值为0,标准差为0.1的高斯分布
Dual GPU
使用了两个NVIDIA GTX 580 3GB GPU
每个GPU有一半的kernel,且只在一些特定的层,GPU之间才进行通信:
- 第2、4、5卷积层的输入只连接了位于同一GPU的前一层的kernel;
- 第3层连接了第2层所有kernel(两个GPU的);
- 全连接层是与前一层所有神经元连接的(两个GPU的)。
LRN(Local Response Normalization)局部响应归一化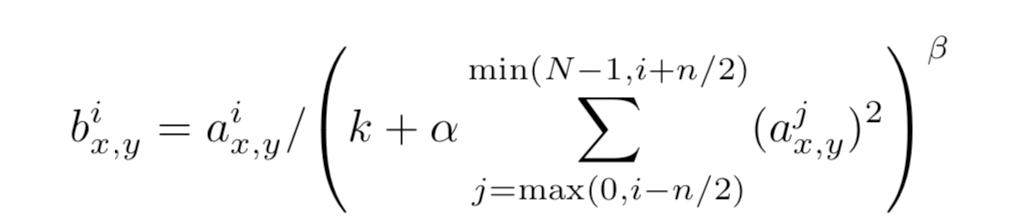
作者发现进行局部的标准化可以提高性能。
- 其中a代表在feature map中第i个卷积核(x,y)坐标经过了ReLU激活函数的输出,n表示相邻的几个卷积核。N表示这一层总的卷积核数量。k, n, α和β是hyper-parameters,他们的值是在验证集上实验得到的,其中k = 2,n = 5,α = 0.0001,β = 0.75。
- 这种归一化操作实现了某种形式的横向抑制,这也是受真实神经元的某种行为启发。
- 卷积核矩阵的排序是随机任意,并且在训练之前就已经决定好顺序。这种LPN形成了一种横向抑制机制。
Overlap Pooling
在池化层提取结果时,会受到相邻pooling单元的影响,有可能结果重复,即相邻池化单元有重叠部分,实验结果表明这比传统池化要好,在Top-1和Top-5上分别提高了0.4%和0.3%。
Drop Out
文章以0.5的概率将每个隐层的神经元输出置为0,dropout减少了神经元互适应性的复杂度,隐层中任何一个神经元都可能会以0.5的概率被丢弃,神经元无法依赖于其他特定的神经元而存在,因此这会迫使网络学习更为健壮、鲁棒的特征。运用了这种机制的神经元不会干扰前向传递也不影响后续操作。dropout减少了过拟合,也使收敛迭代次数增加一倍。