@LoyFan
mathjax: true
General Noun
batchSize 批尺寸 iteration 迭代,使用一个batchsize训练一次 epoch 迭代次数,使用全部样本训练一次
batchSize * iteration = 1 epoch
激活函数总结
其中 z 为神经元输入
- linear
- sigmoid
- tanh
- ReLu
- LeakyReLu
- ELU (Exponential Linear Units)
- MaxOut层
神经元计算公式
k是超参。
- SoftMax层
神经元计算公式(softmax值)
Loss Function损失函数总结
- MSE均方差损失(二次代价函数、平方误差函数)
- Cross-entropy交叉熵损失(对数损失函数)
- MAE绝对值损失
- 指数损失
- Huber损失
- Hinge损失
梯度消失和梯度爆炸
超参数hyperparameter
在机器学习的上下文中,超参数是在开始学习过程之前设置值的参数。 相反,其他参数的值通过训练得出。
- 超参数:
定义关于模型的更高层次的概念,如复杂性或学习能力。
不能直接从标准模型培训过程中的数据中学习,需要预先定义。
可以通过设置不同的值,训练不同的模型和选择更好的测试值来决定 - 超参数的一些示例:
树的数量或树的深度
矩阵分解中潜在因素的数量
学习率(多种模式)
深层神经网络隐藏层数
k均值聚类中的簇数
卷积层Convolution
我们选取一个给定大小宽度和高度的滤波器(filter),将图片分成多个小块patch(patch大小与filter大小相同),用这个filter对图片的第一个patch做内积运算,得到一个输出;然后我们可以利用这个filter在水平方向和垂直方向进行滑动(滑动的步长称为stride)从而对图片的不同部分进行聚焦,最终得到下一层图像。如图2.2所示:假设image的size是55,现在用一个33大小的filter对其进行卷积,stride为1,卷积后最终可以得到一个33的convolved feature。如果希望卷积后的图片与输入大小相同,可以在原始图片外外层包裹一圈0,这个行为称之为*padding(pad)。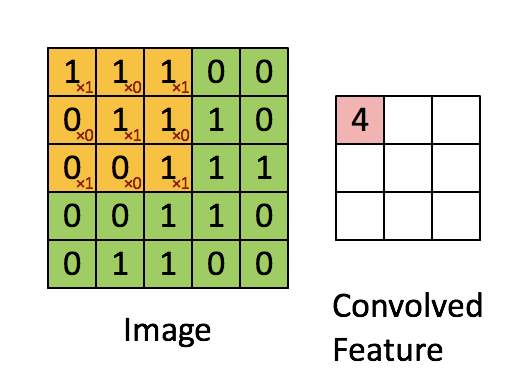
卷积层特点
局部感知:传统神经网络中,每个神经元都要与上层所有像素链接;而卷积神经网络中每个神经元的权重个数均为卷积核的大小,即每个神经元只与图片部分像素相连接。
多核:每个卷积层可以有多个filter,每个filter对上层图片卷积操作后得到的图像就是该filter提取到特征的映射,即一个特征图(feature map)。不同的卷积核,提取到不同的特征。
参数共享:一张图片进行卷积操作时,卷积核的权重不变,一幅图片中不同位置的相同目标,提取到的特征是相同的。参数共享在降低了网络模型复杂度的同时与局部感知一样,极大程度的减少了运算量。
池化层MaxPooling Layer
主要是为了降低数据维度,减少数据和参数的数量,并赋予了模型对轻量形变的容忍度,增强了模型的泛化能力,在一定程度上减小过拟合。
全连接层Fully Connected Layer
两层之间所有的神经元都有权重链接,和传统的神经网络链接方式一样。
MaxOut层
SGD 随机梯度下降
相对于批量梯度下降,随机梯度下降每次更新是针对数据集中的一个样本求损失函数,然后对其求相应的偏导数,SGD运行速度大大加快。SGD更新值的方差很大,在频繁的更新之下,目标函数会有剧烈的波动。当降低学习率的时候,SGD表现出了与批量梯度下降相似的过程。
Dropout
典型神经网络的训练流程是,将输入通过网络正向传播,然后将误差进行反向传播,进行权值更新。Dropout是针对上述过程中,临时随机删除部分神经元(本次不训练临时删除神经元对应的链接权重)。通过dropout处理,有效减少了神经元之间的共适应性,增强了模型的鲁棒性,同时也减小了过拟合的发生。
fine-tune
Finetune model属于迁移学习的一种。在实际运用当中,由于训练时间的限制和训练样本过大的原因,很少有人从头开始训练网络模型,常见的作法有两种:
一是把预训练的CNN模型当做特征提取器;例如使用在ImageNet数据集上的预训练模型,去掉top的全链接层,然后将剩下的网络结构当做一个特征提取器。将数据集输入这个特征提取器中,去除top全链接层网络的输出即为我们提取到的特征,将得到的特征用线性分类器(例如svm或者softmax等)来进行分类图像。
二是fine-tune卷积网络。除了去掉top的全链接层,在网络top端搭建我们自己的分类器之外,我们需要在网络训练过程中对网络模型的后面几层或者是全部层进行权值更新。通常,由于前面几层提取到的是图像的通用特征(例如例如色彩、边缘、简单的图形等),后面几层是针对特定类别有关的特征,因此一般我们fine-tune卷积网络的后边几个层。
批量标准化BatchNormalization
数据带入模型之前,通常会有预处理过程,将输入数据中心化、归一化处理,以帮助模型进行学习训练,随着参数更新,除了输入层之外的其他各层网络的输入数据分布都会发生变化,这将影响网络的训练速度。
BN算法就是为了解决再训练过程中,中间层数据分布发生变化的情况下的数据归一化。
批量标准化对每小批数据都从新进行标准化,在模型中加入批量标准化后,能使用更高的学习率而且不在对初始化参数特别敏感。
批量标准化可以看做是一种正则化手段,提高了网络泛化能力。
embedding
自编码器AutoEncoder
IntroductionLink
自动编码器是一种数据的压缩算法,其中数据的压缩和解压缩函数是数据相关的、有损的、从样本中自动学习的。在大部分提到自动编码器的场合,压缩和解压缩的函数是通过神经网络实现的。
自动编码器是数据相关的(data-specific 或 data-dependent),这意味着自动编码器只能压缩那些与训练数据类似的数据。比如,使用人脸训练出来的自动编码器在压缩别的图片,比如树木时性能很差,因为它学习到的特征是与人脸相关的。
自动编码器是有损的,意思是解压缩的输出与原来的输入相比是退化的,MP3,JPEG等压缩算法也是如此。这与无损压缩算法不同。
自动编码器是从数据样本中自动学习的,这意味着很容易对指定类的输入训练出一种特定的编码器,而不需要完成任何新工作。
搭建一个自动编码器需要完成下面三样工作:搭建编码器,搭建解码器,设定一个损失函数,用以衡量由于压缩而损失掉的信息。编码器和解码器一般都是参数化的方程,并关于损失函数可导,典型情况是使用神经网络。编码器和解码器的参数可以通过最小化损失函数而优化,例如SGD。
自编码器是一个自监督的算法,并不是一个无监督算法。自监督学习是监督学习的一个实例,其标签产生自输入数据。要获得一个自监督的模型,你需要一个靠谱的目标跟一个损失函数,仅仅把目标设定为重构输入可能不是正确的选项。基本上,要求模型在像素级上精确重构输入不是机器学习的兴趣所在,学习到高级的抽象特征才是。事实上,当主要任务是分类、定位之类的任务时,那些对这类任务而言的最好的特征基本上都是重构输入时的最差的那种特征。
目前自编码器的应用主要有两个方面,第一是数据去噪,第二是为进行可视化而降维。配合适当的维度和稀疏约束,自编码器可以学习到比PCA等技术更有意思的数据投影。
对于2D的数据可视化,t-SNE(读作tee-snee)或许是目前最好的算法,但通常还是需要原数据的维度相对低一些。所以,可视化高维数据的一个好办法是首先使用自编码器将维度降低到较低的水平(如32维),然后再使用t-SNE将其投影在2D平面上。
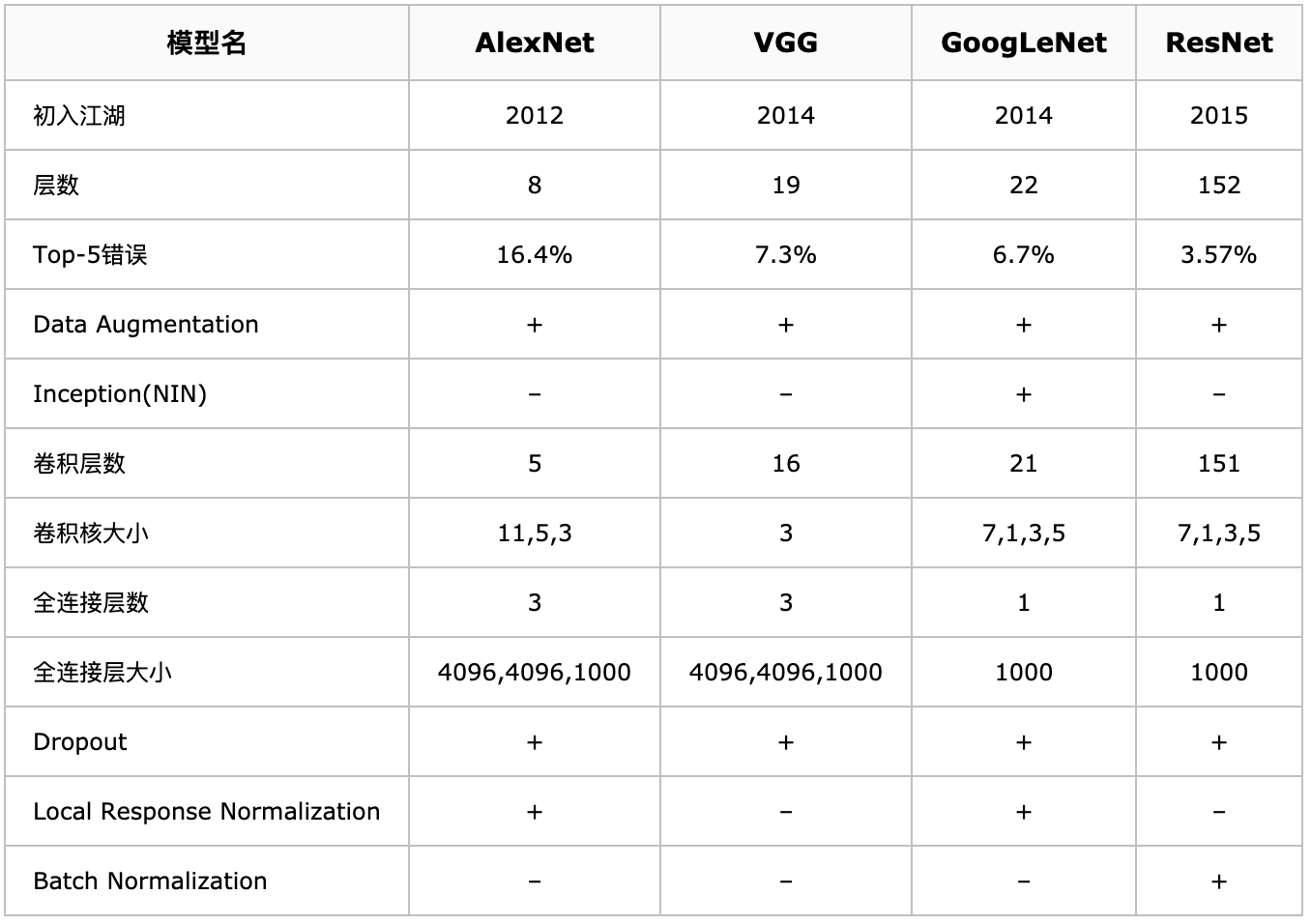
Neural Network Models
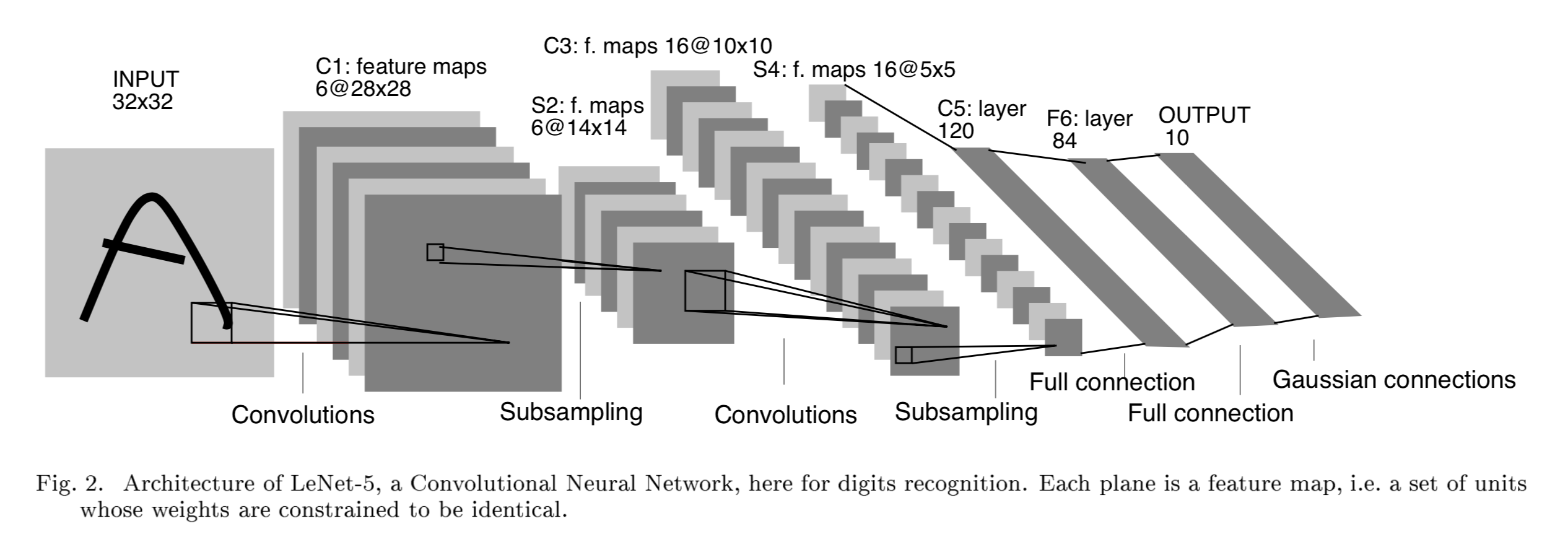
LeNet 1989
A layered model composed of convolution and subsampling operations followed by a holistic representation and ultimately a classifier for handwritten digits.
AlexNet 2012
NIPS2012 PaperLink
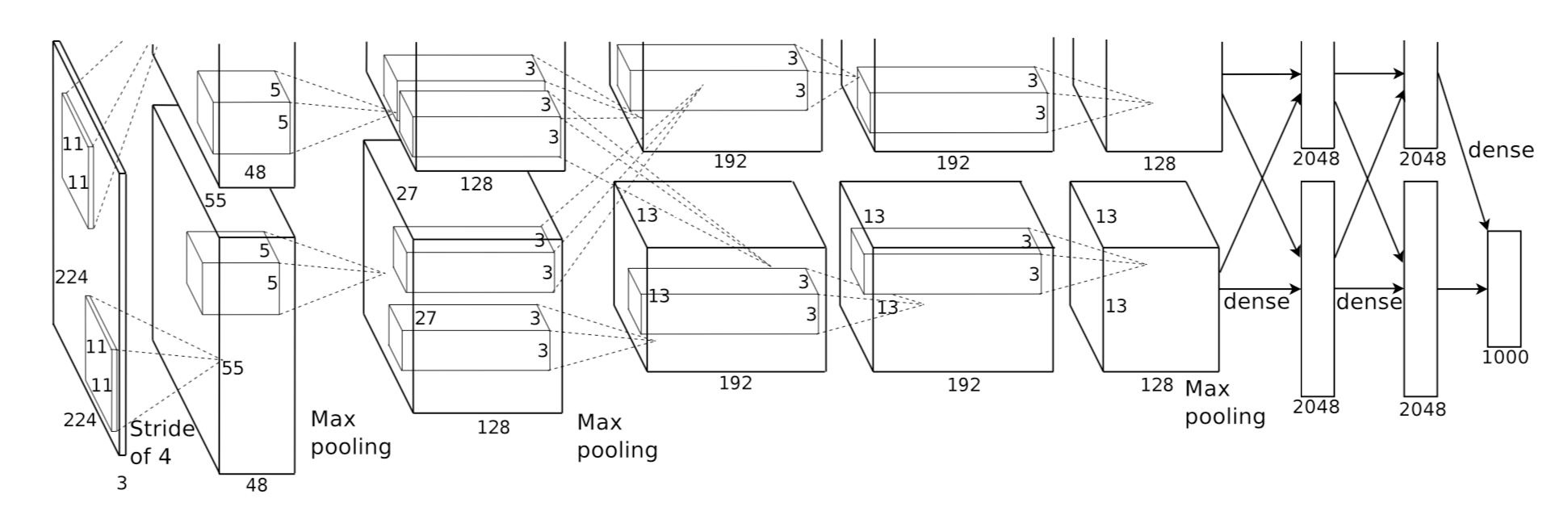
基本参数:
输入:224×224大小的图片,3通道
第一层卷积:11×11大小的卷积核96个,每个GPU上48个。
第一层max-pooling:2×2的核。
第二层卷积:5×5卷积核256个,每个GPU上128个。
第二层max-pooling:2×2的核。
第三层卷积:与上一层是全连接,3*3的卷积核384个。分到两个GPU上个192个。
第四层卷积:3×3的卷积核384个,两个GPU各192个。该层与上一层连接没有经过pooling层。
第五层卷积:3×3的卷积核256个,两个GPU上个128个。
第五层max-pooling:2×2的核。
第一层全连接:4096维,将第五层max-pooling的输出连接成为一个一维向量,作为该层的输入。
第二层全连接:4096维
Softmax层:输出为1000,输出的每一维都是图片属于该类别的概率。
ZF-Net
VGG 2014
GoogleNet 2014
CVPR2015 paperlink
Inception V1
Inception V2
xception
ResNet 2015
CVPR2016 Best Paper PaperLink
解决退化问题:
随着网络层数的增加,模型的准确率下降了,这种退化并不是由过拟合造成的,在一个合理的深度模型中增加更多的层却导致了更高的错误。
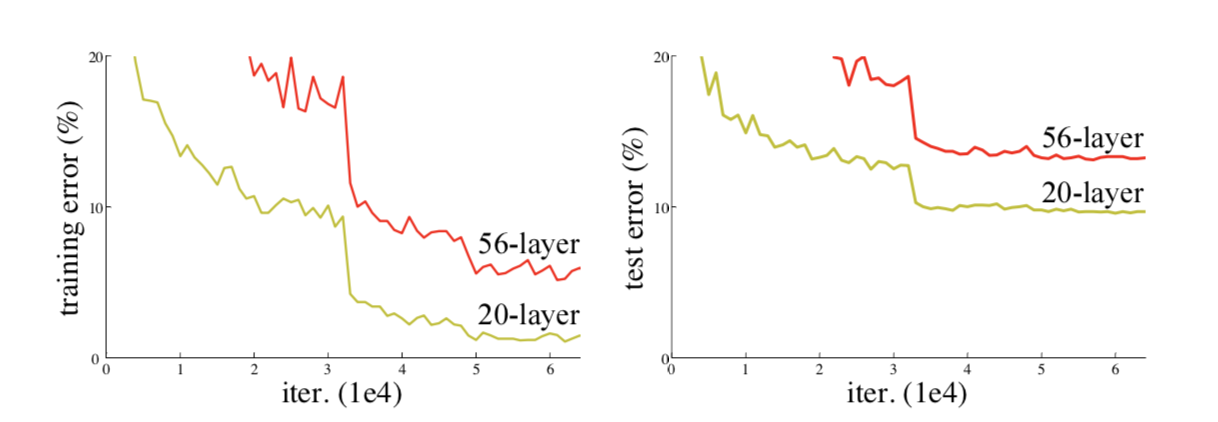
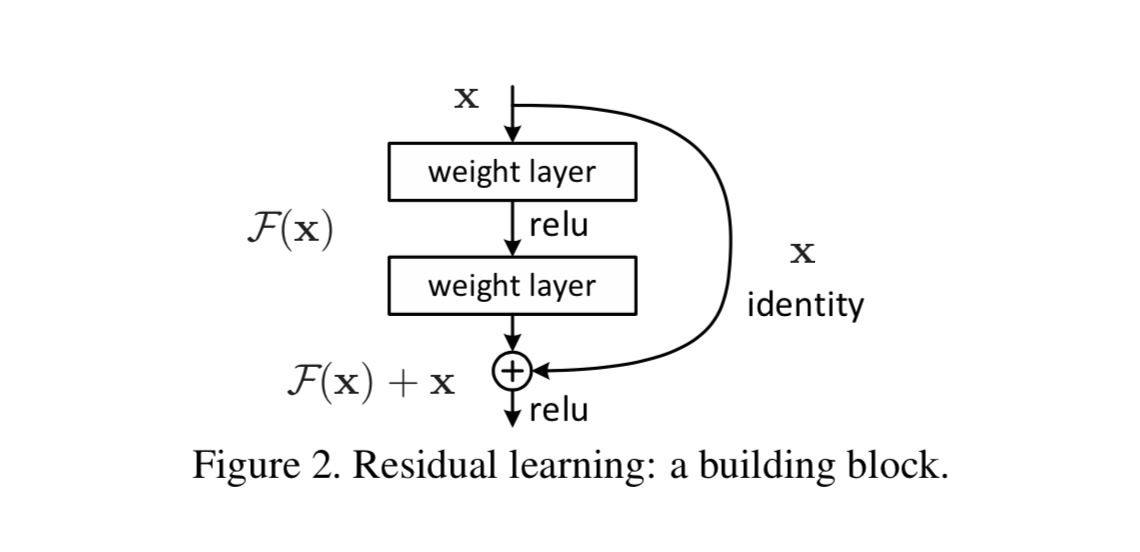
残差学习:
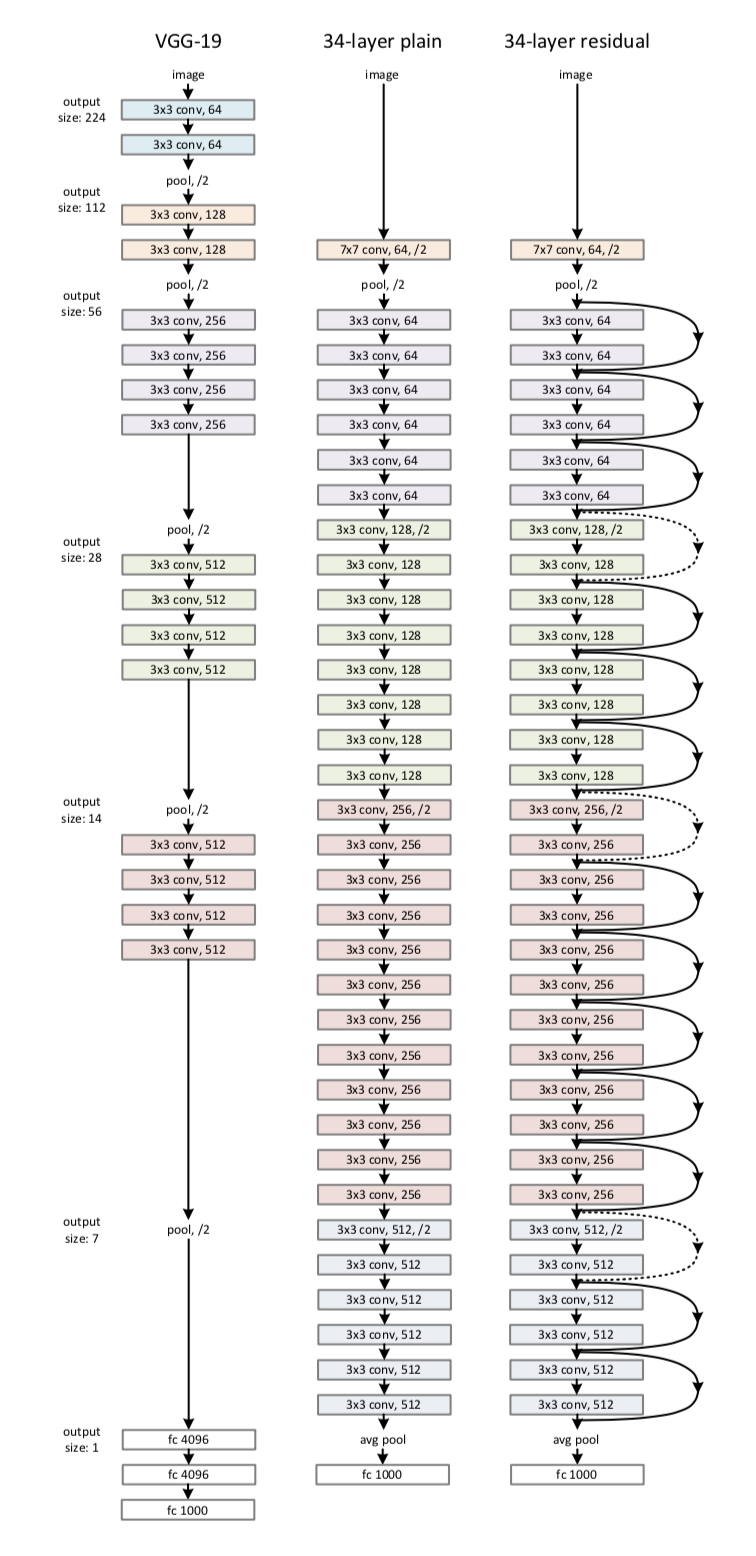
网络结构:
DenseNet
CVPR2017 Best Paper PaperLink
GAN 生成对抗
R-CNN Regions with CNN features
RCNN
CVPR2014 PaperLink
fast-RCNN
faster-RCNN
NASNet
FCN全卷积网络